
Originally published here
When designing and building systems that follow a service-orientated paradigm, we find that the complexity of securing the overall system and choosing a pattern for authentication can be challenging. Building a centralized monolithic system would mean that your authentication and authorization are also central, that there is one authority determining which end-users have access, and what those users have access to. With a distributed system, you need to ensure that the user has the necessary access and permissions to interact across multiple services. Another aspect would be that internal services themselves require the necessary access and permissions to interact with one another.
With systems evolving and becoming more complex as new services are introduced into the ecosystem, scalable and robust authentication and authorization methods and practices are required to ensure that the security posture of a system is maintained.
Single Entry Point for External Traffic – API Gateway
For handling security across multiple services, a good approach is to consider an API gateway to expose interfaces to the public internet, and keeping the services themselves internal and only accessible within a private network. By doing this, you control the entry points of traffic coming from the public internet, the main attack surface of any system, as bad actors will attempt to approach the system from the public domain, looking for vulnerabilities to exploit in your systems authentication mechanisms or lack thereof.
By setting up an API gateway, you can achieve the following:
- You have a public endpoint where you can monitor and control the flow of public traffic – if your public entry points into your system are consistent and not affected by changes to your internal systems, it is easier to protect and manage.
- Put a web application firewall (WAF) in front of your public entry point – Configure and set up a firewall that suits your ecosystem, instead of having to apply WAF rules per service as this can be an issue to maintain when every service you develop is exposed to the public internet individually.
- Hide your domain and any internals from the public internet – the less information an attacker can gain about the internal workings of your system, the harder it is to compromise.
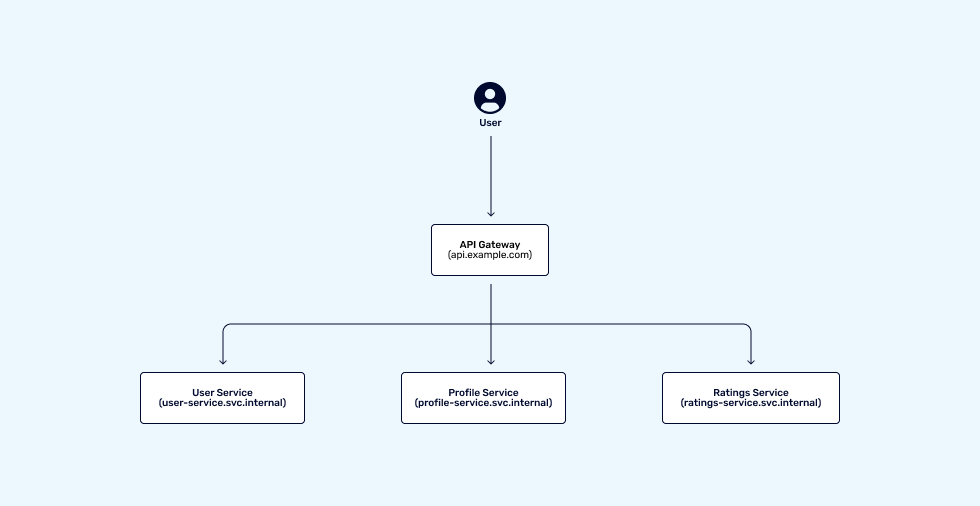
Now that you have visibility and control over the public traffic coming into the system, now you need to look at your authentication mechanism.
Authentication – Use what Exists, Don’t Build your own
A challenge is finding custom authentication mechanisms in an ecosystem, usually built around business requirements that didn’t align with what was out there, OAuth2 potentially being too barebone, and a business needing more granular and complex flows. Our approach is always the same when looking at the architecture authentication within a distributed system, and our primary rule is don’t roll out your own authentication.
Many authentication methods have been battle-tested over years, have a specification that needs to be adhered to, are community maintained, and were built by security experts. To build your own authentication system means that you are taking the risk of going through the teething problems of starting a new authentication solution, and that is managing early design flaws and vulnerabilities, something that is not ideal for a system in production.
Two things to look at with Authentication and Authorization:
- Authentication – Identifying who the user is and if they are who they say they are.
- Authorization – Determining what that user has access to.
Authentication and authorization are the foundation to keeping systems secure, and existing solutions will have a focus on doing one of these actions, and doing them well.
Adding auth inside the ecosystem should look like this:
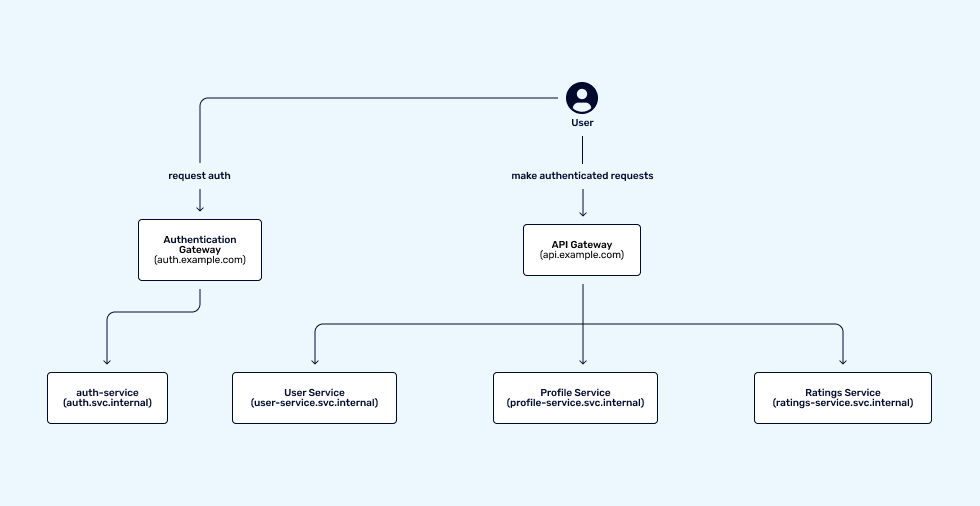
In this example, the auth-service acts as a facade in front of your chosen authentication method. Say, for example, you have a simple single-page frontend application that you want to rate planets. To achieve this, you want to be able to identify users (login) and want to associate a rating with each user (permissions).
For this, you can use the OpenID connection specification (OIDC) which is a maintained specification on top of OAuth2 that allows for the authorization code flow with PKCE, which is suited for frontends running on the client-side that cannot hold any authentication credentials for OAuth2.
The approach to this can be a self-hosted, or SaaS solution. When looking at SaaS solutions you have options like Auth0 and Okta, and should you want to host your own running instance of an OIDC implementation, you can use any of the certified OIDC provider implementations based on your stack.
Any business rules should be an extension of your authentication mechanism, and the trusted solution should always be at the core of your authentication, for example, if your business rules require custom claims that are not default in OIDC, the approach would be to follow the specification and add custom claims instead of building auxiliary services that fall outside of the specification and introduce components not thoroughly battle-tested and security hardened. Always think of it from the perspective that if you generate JWTs yourself for authentication using a JWT library, chances are a misconfiguration or security vulnerability introduced by writing the logic in-house.
Once you have your authentication mechanism set up, your users can authenticate against your auth-service, and receive a token (JWT) in return to communicate with your gateway, you now need to rely on identifying users in that ecosystem.
Identifying Your Users – Letting Services Know Who’s Who
With users being able to authenticate and communicate securely with your gateway, your user needs to be identified so that context can be passed to your internal services.
An example would be a user is authenticated and now provides a token in the Authorization header, the API gateway in this example, would be able to verify that token, and get the context of that user.
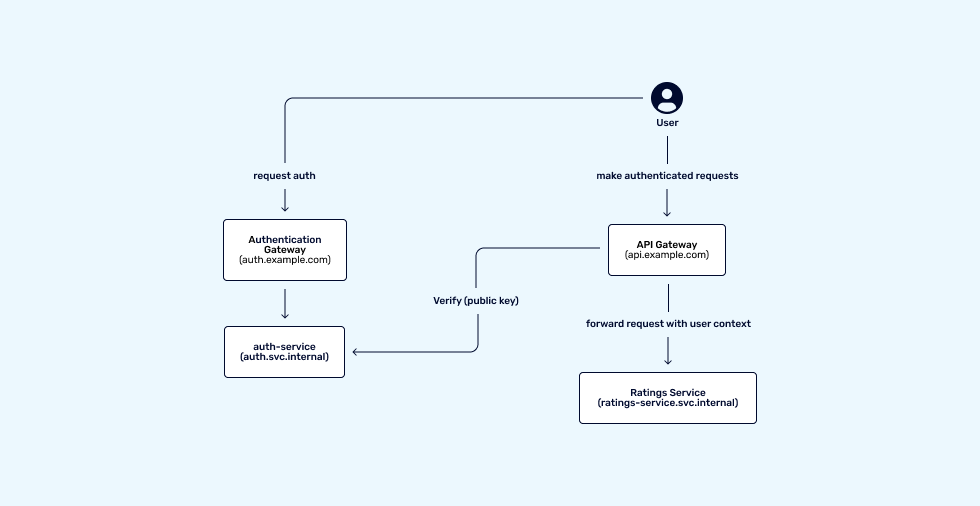
This is where organizational requirements come into play, and trust boundaries need to be defined.
We look at the following:
- Low Trust – We trust everyone in the internal network, and we can map a JWT to a user’s unique identifier, and pass that to any internal service along with the claims (permissions).
- Zero Trust – We don’t trust anyone, assume anyone on the internal network could be a bad actor, and pass short-lived context in the form of user tokens generated for internal use.
Both these approaches have their own advantages and disadvantages in their implementation, as something like zero-trust brings about a lot of overhead and potential coupling to centralized auth, whereas low trust would allow services to be decoupled, at the expense of a bad actor on the internal network being able to make a request on an authenticated user’s behalf.
Below is an example of how a user interacting with ratings would result in a low trust environment vs. a zero-trust environment.
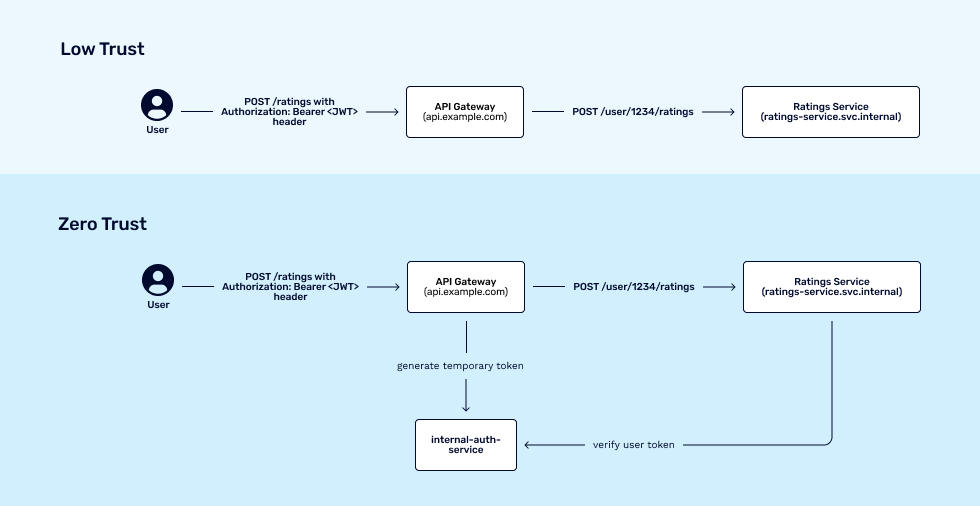
From the example, Low Trust would be the easier solution, provided that you trust all actors in the internal application network, which in this case would never be guaranteed, and the risk differs per organization.
With Zero Trust, you are potentially introducing a central authority that controls the translation from the user JWT to a temporary token that can be used by services for the lifespan of a request, meaning that only the external user can make that request under normal circumstances.
Once it’s been determined how users will be identified in the ecosystem, next is to look at how data flows through the system, and understanding what kind of data is passed by users and returned to users.
Service to Service communication – Is Encryption at Rest Enough?
Encryption is a major factor to account for in systems and comes back to the trust boundaries defined by the organization:
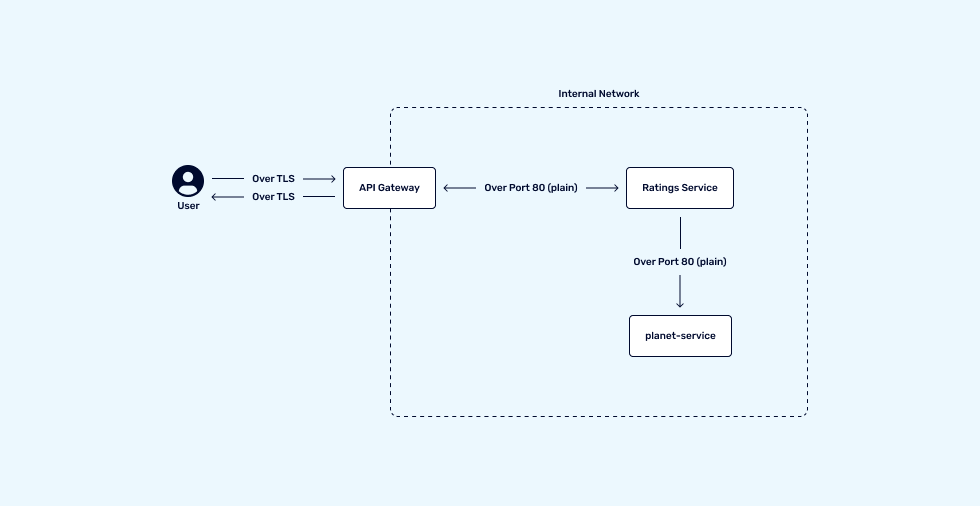
- Low Trust – We trust everyone in the internal network, given the necessary permissions, everything leaving the network is encrypted at rest, but we are aware that plain-text communication exists between services.
- Zero Trust – We don’t trust the network layer, and everything needs to be end-to-end encrypted from the moment it enters the infrastructure to its interaction between various services, as well as data that leaves the infrastructure.
An example of this would be in a Kubernetes cluster, where a user communicates with the API gateway using TLS, and the gateway is responsible for forwarding that request to a service, and during that interaction, the service will need to downstream make calls to other services.
The diagram below represents a simple setup with Low-trust:
For security requirements requiring stricter security policies, an approach to take is mutual TLS (mTLS) between all services:
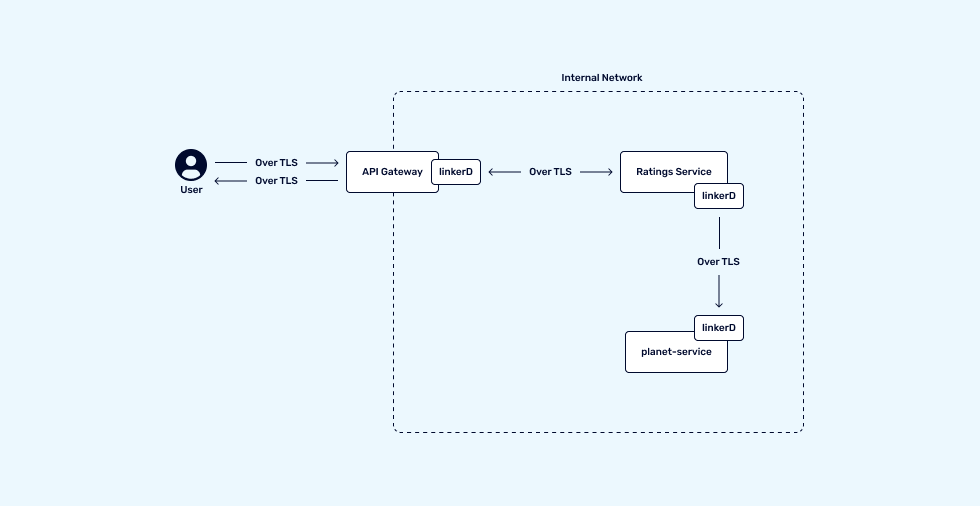
In this example, a service mesh like LinkerD to apply mTLS across a control plane, removing the responsibility of each application maintaining certificates and TLS handshakes. What this creates is encrypted communication within an internal network, and removes the concern of plain-text communication between services.
Although it adds complexity to the infrastructure setup and maintenance, the monitoring advantages of a control plane by means of introducing a service mesh will be beneficial to an ecosystem overall.
Knowing Your System’s Trust Boundaries
Every system has different requirements when it comes to security, and can range from the type of service provided, to policy requirements needed to adhere to compliance standards. Security mechanisms should be designed with this in mind, and take into account the trust boundaries so the needed degrees of security can be applied to the ecosystem.
Security is an evolutionary process in a system and will improve and evolve as the system grows, but ensuring that the foundation is good in the early stages is important in maintaining a good security posture – build with security in mind instead of retrofitting at the later stages.
We look forward to hearing more from Deimos at Africa Money and DeFi Summit later this month
The Africa Money & DeFi Summit will connect African fintech, payments & crypto leaders, global platforms and thought leaders on the new opportunities in Decentralized Finance (DeFi) in Accra Ghana on September 27th & 28th 2022. An array of keynotes, panels and breakout sessions will deliver key insights and offer opportunities to connect, network and do business across the African fintech and DeFi landscapes. Register today
